RAG chunking isn’t one problem, it’s three

Chunking in RAG refers to splitting a source-document into a smaller piece to isolate relevant information and reduce the number of tokens you’re providing to an LLM before it writes an answer
You have a shiny RAG system powering your customer knowledge base. A customer asks how to cancel their Enterprise subscription. Your system retrieves a chunk about ‘cancellation’ from the Terms of Service as strongly relevant … but that chunk doesn’t mention that Enterprise plans require 90-day notice - that’s three paragraphs later under ‘Notice Periods’.
OK fine. You make your chunks bigger to capture more context, but now your ‘cancellation’ chunk also includes refunds, billing cycles, and payment methods. The embedding is diluted. Searches for ‘refund policy’ start returning this monster chunk. How about overlapping chunks? Better recall, but now you’re stuffing even more redundant information into your prompt, responses are taking a long time to generate and sometimes wander off on a tangent.
The wunderkind junior dev hits on an ingenious solution: you use the LLM to generate small and punchy summaries of the chunks using the LLM itself, that pull in important context. This works well until you get a call from Legal saying a customer is quoting from the Terms and Conditions, but the Terms and Conditions don’t actually say the thing they’re quoting – the LLM is quoting its helpful summary instead. Nobody’s happy.
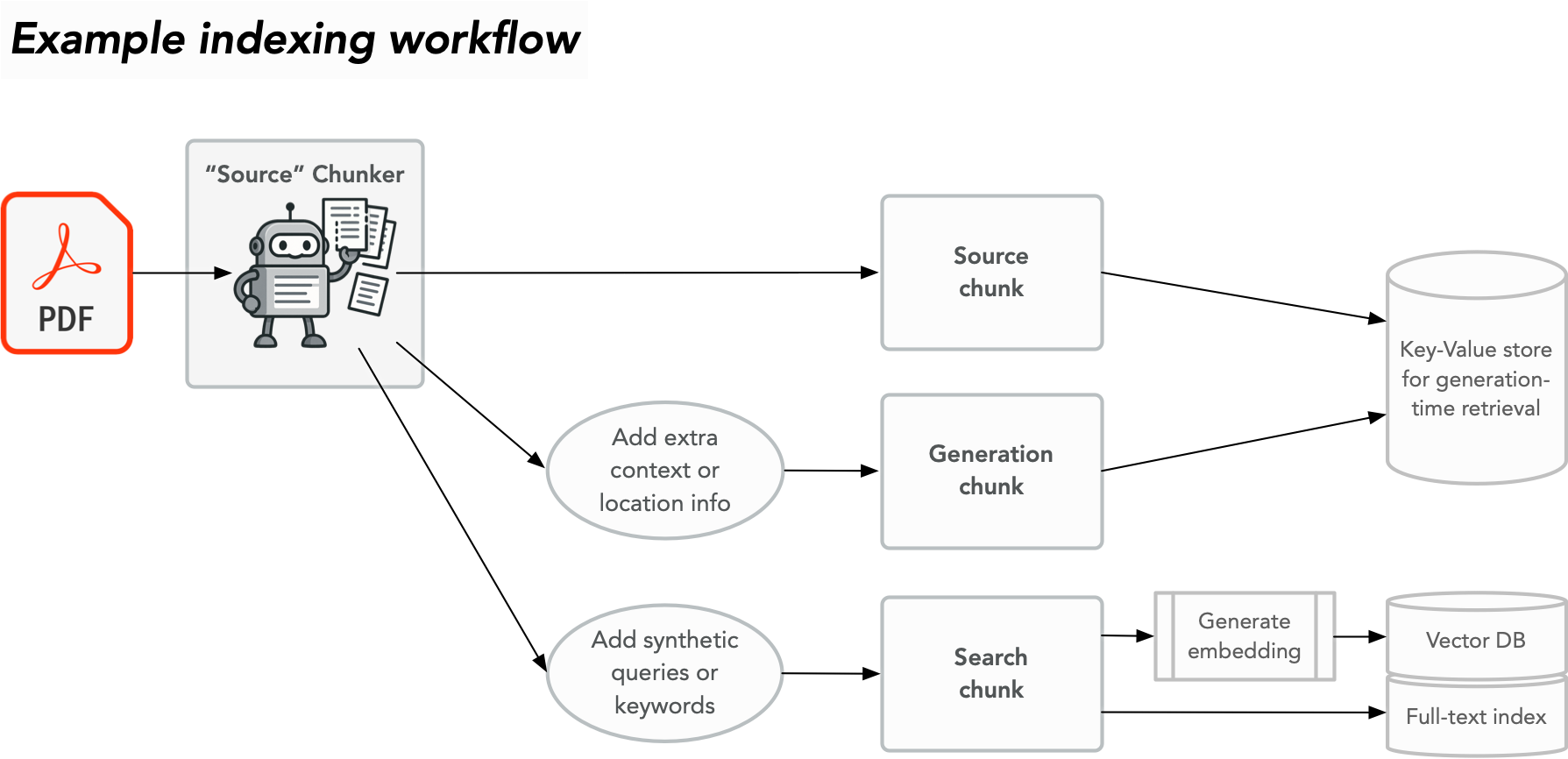
Existing articles often focus on a chunk as a singular concept: you split the article into paragraphs, say, and this paragraph must:
- Provide sufficient information to the LLM to help it craft an answer
- Make a high-quality embedding and BM25 (keyword-matching) target
- Be a high-fidelity source document that we can quote back to the user
But that’s three problems to solve, not one problem Trying to solve all three problems with a single chunk of text is painful, which is why we have a whole flotilla of adjunct solutions like re-rankers.
There’s nothing stopping you solving these problems individually and well.
Generation chunk
Arguably the most important job your chunk needs to do is to provide the LLM with “just the right amount” of information to answer the question. Too little and you risk reduced accuracy by missing important details, too much and you end up with slow, expensive responses that include irrelevant detail or get confused.
The right approach here is heavily content-dependent, but:
- This doesn’t literally have to be the source content; you can have an LLM rewrite this for you to include important context, to expand out things that would otherwise be implied by the position in the document, and so on
- You can also just sign-post where a piece of content came from directly to the LLM as context by prepending the document structure to the text
Embeddings and or/keyword search chunk
Generating an embedding from the same model for both a user’s question and a given chunk of content works well enough as an approach that it’s the backbone of most RAG systems, but it also works poorly enough that tweaking the embedding model or reranking is usually the first port of call for fixing misbehaving RAG applications.
You don’t have to use the same text you’re feeding the LLM as a direct input for the embedding model. You can instead stuff in key words before doing it (for hybrid systems also using BM25 or similar), you can ask the LLM to generate 25 questions that this chunk would answer in context and append it to the text before generating the embedding, or really you can do whatever works well for your content.
This is really the key idea of the article: you don’t have to be tied to the same chunks you’re feeding the LLM as the source of your embeddings if something else would work better for you (which you’ll discover using your evals).
Source document chunk
The source document chunk is the unvarnished, unaltered, verbatim source text that births the embedding chunk and the generation chunk, and if you are directly quoting anything to the user, this needs to be where the quote comes from: if you quote a chunk you’ve synthetically constructed for embedding or generation, you may well be about to cause yourself some serious problems! You’ll also probably want to anchor this to precise location metadata about the source, whether that’s a page and paragraph in a source PDF, a clause in a legal contract, or just a URL.
Not every RAG setup is going to need a distinct chunk for this: if you have a RAG system over a set of forum posts for an online game, then you may well only need to retain the source text for debugging, and the generation chunk will be sufficient.
However, in situations where it’ll matter:
- Two-step citations: there’s nothing to stop you providing the literal source chunk to the LLM after it’s performed its initial analysis on a chunk you’ve modified to aid generation, to help it bolster its answer or provide citations; as long as you have a shared ID between them, you can add an explicit citation step; if you wanted to get really fancy and have tokens to burn you could make this an MCP service
- Single-step citation: there’s also nothing stopping you providing both the source text and the expanded text to the LLM at initial generation time, clearly labelling both, and combined with instructions on which can be quoted
Conclusion
Trying to solve the three ways your RAG chunks are going to be used with just one single chunk puts an awful lot of weight on whatever your chunking strategy is. By starting with meaningful source-chunks from your document that represent document parts, and then creating more useful embedding- and generation-specific chunks, you don’t need one solves-all chunking strategy, you can focus on use-case specific chunking strategies.